A large language model (LLM) is a compressed representation of human knowledge. It is only as powerful as the data that it was trained on.
The volume of data that OpenAI used to train their most powerful models is on the order of terabytes, 10 to the power of 12.
At the same time, the entire volume of data generated by the world economy is estimated at 64 zettabytes, 10 to the power of 21. 90% of this volume was created in the last two years, and the volume of data doubles in size every two years.
GPT-4 finished training at some point in the past. Needless to say, its compressed representation of human knowledge is incomplete and outdated.
On the bright side, LLMs are excellent few-shot learners. They can respond to requests based not only on their internal representation of knowledge but also on data provided as part of the request, the so-called “context.”
For instance, if we provide an LLM with the latest news stories about a brand, the LLM can perform current and accurate sentiment analysis for that brand.
If the data provided in the context is not sufficient, LLMs can be instructed to request more data, e.g. by performing a database query or calling an enterprise application.
We are now ready to define the new semantic broker category.
A semantic broker is an element of the enterprise infrastructure that directs the flow of control and data among LLMs, their end users, and other elements of the enterprise infrastructure: databases, warehouses, data lakes, CRM, CMS, DAM, ERP, EHR, and other types of systems.
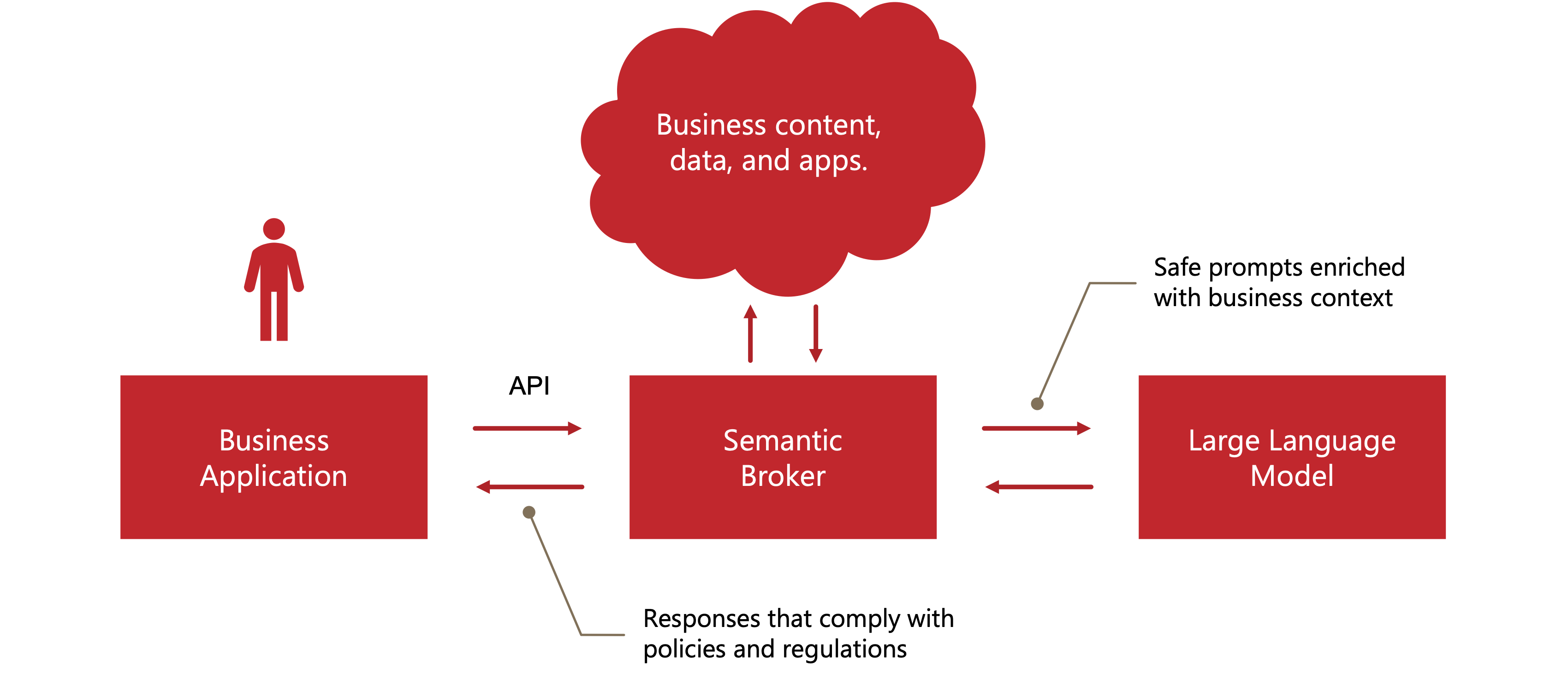
The semantic broker is also responsible for risk management. It is its most unique and interesting capability.
LLMs are inherently stochastic systems. Their power is maximized if they are designed to randomly vary their responses, and they do hallucinate at times.
Consequently, deployment time testing must be augmented with runtime risk management. The semantic broker is responsible for performing this risk management function.